The Need for Data Masking in a Data Warehouse
Data in organizations are not leveraged as much as it can be, and often they rely on making decisions using expert opinions in most cases. The decisions will be more meaningful and powerful when backed with intelligent data relative to the needs of data consumers using data silos and warehouses.
According to the magazine Supply and demand chain executive, North America will be the dominant market for data warehousing exceeding 40% by 2025 and reaching the $30 billion mark.
The best way to manage data in silos effectively and efficiently is to create data warehouses that store data from various sources in one place. Data warehouses facilitate instrumental data-driven decisions at enterprise scale by incorporating highly sophisticated data storage and management architectures. Therefore, it is essential to know the best practices that can be included in achieving this and decide on taking an approach that works/aligns with the Organization’s functional and operational methods and processes.
Start Your 14-Day Free Trial
- Pre-built connectors and ready-made integration templates
- Real-time and bi-directional data sync
- Self-healing automation - zero babysitting
What is a data warehouse and why is it important to have one?
Source: https://digitalgreenhouse.gg/news-impact/entrepreneurship/data-warehousing-how-why/?v=pp-6Rl_jvAI
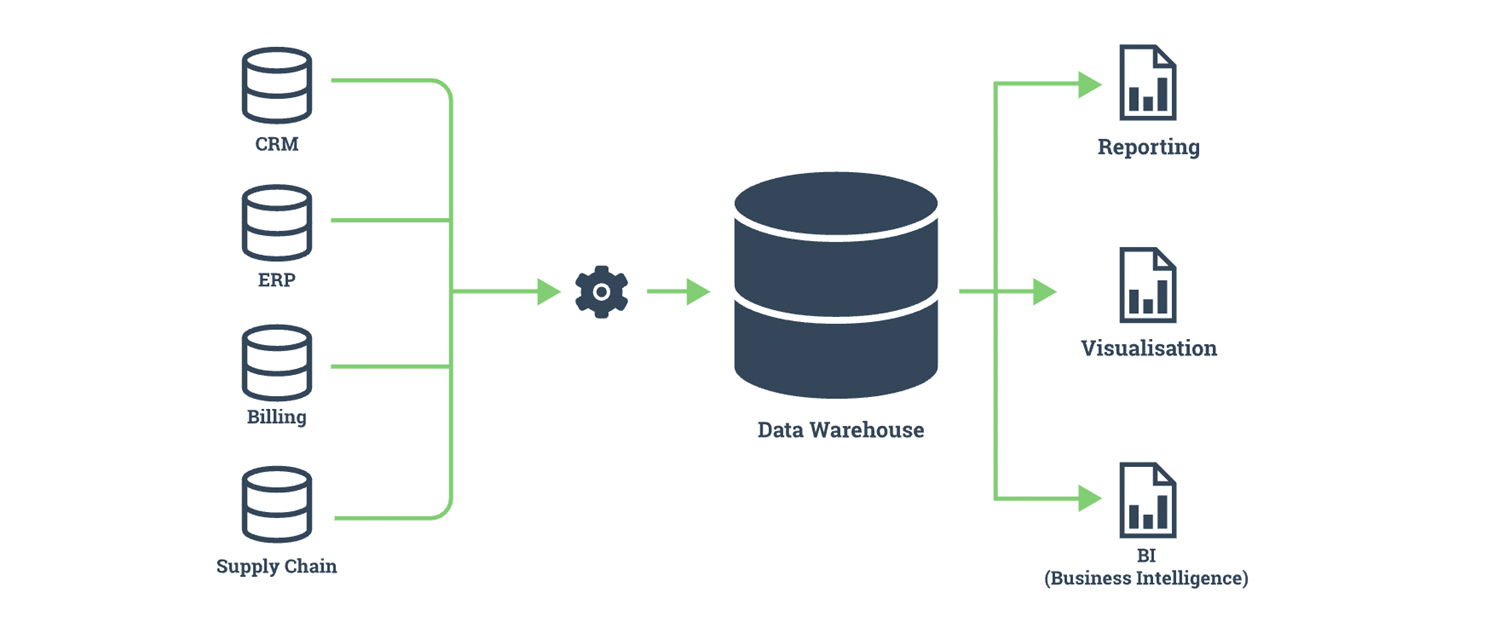
Data warehouses (DWs) are central repositories of integrated data from one or more disparate systems. The data from multiple sources are consolidated to serve as the single source of truth for business intelligence and decision-making within the Organization. Since large-scale data reads and processing functions are inherent for long-running analytics it is essential to set up and maintain data warehouses, where data is prepared, cleaned, and stored to fuel the analysis facilitating reports and dashboards by Business Intelligence systems.
Data warehouses are built to withstand and operate frequent and complex queries at scale which the normal operational databases are not built for, and they integrate well with data lakes and silos supporting more complex analytic capabilities by providing quick queries and high-quality data.
Main components in a Data Warehouse
Data warehouse is a central repository of information from multiple sources, it is important to understand the various components involved to set up a data warehouse. These components are specifically designed for enhanced speed facilitating faster and flawless data analysis.
The main components of a data warehouse are discussed below:
- Central Database – Warehouse database is the first component which serves as the central storage for data, it is typically a relational database hosted on-premise or cloud based.
- ETL tools – ETL (Extract, Transform and Load) tools serve as the central component in setting up a data warehouse by allowing you to extract data from different data resources and transforming to align the data for faster analytic capabilities. Different strategies are employed including ETL, ELT, bulk and real time processing and quality analysis using the tools.
- Metadata – One of the major components include metadata, simply termed as ‘data about the data’. Metadata tells you everything about the data including features, usage, values, score and the technical context.
- Access tools – In order to access and work with the data in the warehouse, various tools are used such as data mining tools, app development tools, OLAP tools, querying and reporting tools.
- Reporting dashboards – In order for deriving insights from the data, reporting dashboards are created using the query and reporting tools enabling customers to implement detailed reports and visualizations.

What is data masking and what is the best way to achieve data security in DWs?
It is very important to protect information from unauthorized access as there will be lots of sensitive information from different sources in a data warehouse. One of the ways is by making the data incomprehensible using data masking.
Data masking is a way or a technique to create a fake but realistic version of your Organizational data which serves as the functional alternative to the real data. Data masking helps with maintaining the data elements and structure while just altering the information without losing its model.
Data masking can be employed during early stages of setting up and testing Data Warehouses, and some of its advantages are provided below,
- Data masking will ensure that the data is available for tests and they are conclusive and more definite to the actual use case without compromise in data security
- Makes data useless to attacker preventing Data theft and hacking
- Alternate version of DWs can be created identical to actual DW ensuring proper training and testing for different users
- Access rules along with data masking ensures security of data and will help with tracking and analysis of data for breaches or theft
- Can be used for data sanitization without leaving traces of real data
Methods to mask data:
Data privacy is the main use of implementing masking where the confidentiality of information is maintained while providing business value. Masking is usually done within ELT pipelines/tools and some of the masking types are discussed below:
1. Static data mask:
By using static methods to mask data it is easier to protect data during the phase of ETL/ELT as the data extracted will easily be modified to fit simple use cases without much data modeling or modifications to actual data. Static data masking typically is achieved by creating a backup copy of the data in the production database, loading it to a separate environment and then cleaning unnecessary data followed by masking and loading this data back to the target location.
2. Dynamic data mask:
This is a sophisticated method to mask data within databases, one of the best ways to achieve security is by real time reordering/shuffling of data present, the main disadvantage of this type of mask would be with real time changes in databases leading to decreased performance in databases.
Some of the best methods to achieve security is during extraction or On-the-fly data mask reducing the impact on performance of the database. It is done using ETL pipelines as DWs follow ELT by default, ETL ensures data security by transforming data even before it reaches the data storage.
Strategies of data masking vary from company to company and the data modeling methods; but using ETL ensures better database performance as it does not load or cause problems with the database because it is done during the process within ETL tools. Some of the most common masking techniques are discussed below:
- Substitution – Data values are substituted with fake but realistic values.
Example: Customer names are substituted with random names available in a phonebook.
- Scrambling – Data values are changed to symbols/characters and also reordered to not represent the correct values.
Example: Phone numbers can be changed to 101*****12 instead of actual numbers (can use other special characters based on convenience)
- Blurring – Data values are substituted with a range rather than keeping it absolute.
Example: Salary can be represented as $25-$50k instead of representing it as $45,000(will be usually represented as varchar type)
- Shuffling – Data values are randomly rearranged in the columns using random sequences

 Sync data from MySQL to MinIO
Sync data from MySQL to MinIO
 Sync data from MySQL to SQL Server
Sync data from MySQL to SQL Server
 Sync data from Azure Synapse to SQL Server
Sync data from Azure Synapse to SQL Server
Example: Values such as ID can be randomly shuffled for each row
If the data present in the table is
| 200 | John |
| 201 | Caleb |
| 202 | Rich |
The ID column values can be rearranged to
| 202 | John |
| 200 | Caleb |
| 201 | Rich |
- Randomizing – Data values are replaced by generating random fake values
Example: ID values can be generated based on a sequence which can be 10,20,30 and so on , instead of keeping the real IDs
- Nulling out – Data values are set to null and not viewable by unauthorized users, this method is less useful for development and testing as it cannot help with deriving any useful business insights.
Example: House number or door number in address can be removed or changed to NULL without representing the actual number
- Pseudonymization – A new term that represents a technique to secure data, usually done by removing any direct or combination of identifiers to derive meaningful information.
Example: Actual Student names for specific courses can be changed to just candidate1, candidate2 etc.
- Encryption – A key is used to transform or change the existing values and stored, only using the same key the data can be recovered and this is the most advanced, sophisticated and secure way to protect data.

How will DBSync help you achieve data masking?
DBSync provides capabilities to achieve data masking while in transit instead of doing it within data warehouses, it works across different databases and brings different mechanisms including both static and dynamic mask methods. The mask patterns can be easily customized and adapted to the existing framework or architecture of data model and storage without the need for additional architectural changes.
Below are some of the mask mechanisms that can be incorporated for data replication to data warehouses.
- Predefined masking patterns – Some of the predefined masking types will get you started with data masking without need to invest significant time in setting up any. Some of the mask types that can be used without any additional configuration are provided for masking phone, credit card, date/time, email and random integer for number type fields.
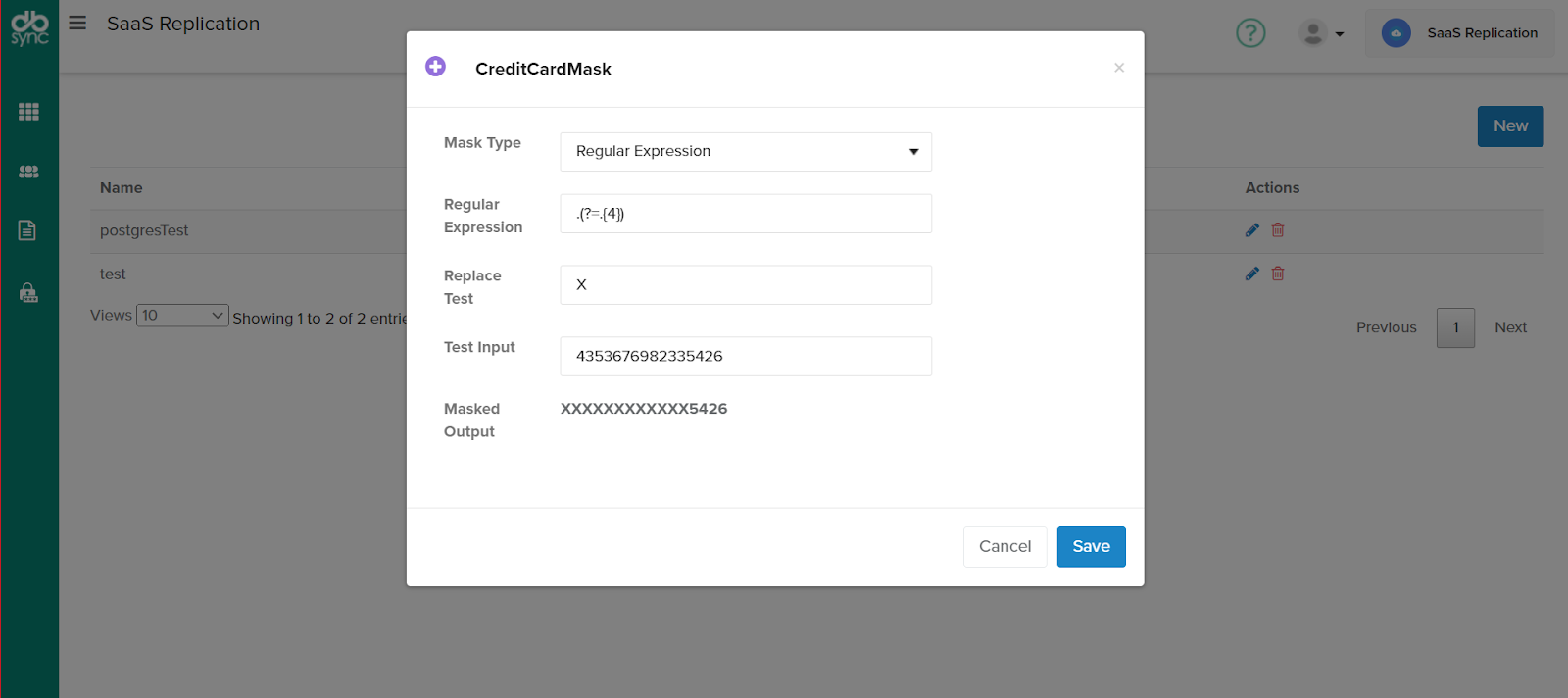
- Custom masking patterns – As the name suggests mask types are configurable based on the need, for example, instead of masking only the last 4 characters with a predefined mask this helps with masking a range of characters as pattern can be defined using regular expressions and then masking with required character or symbols.
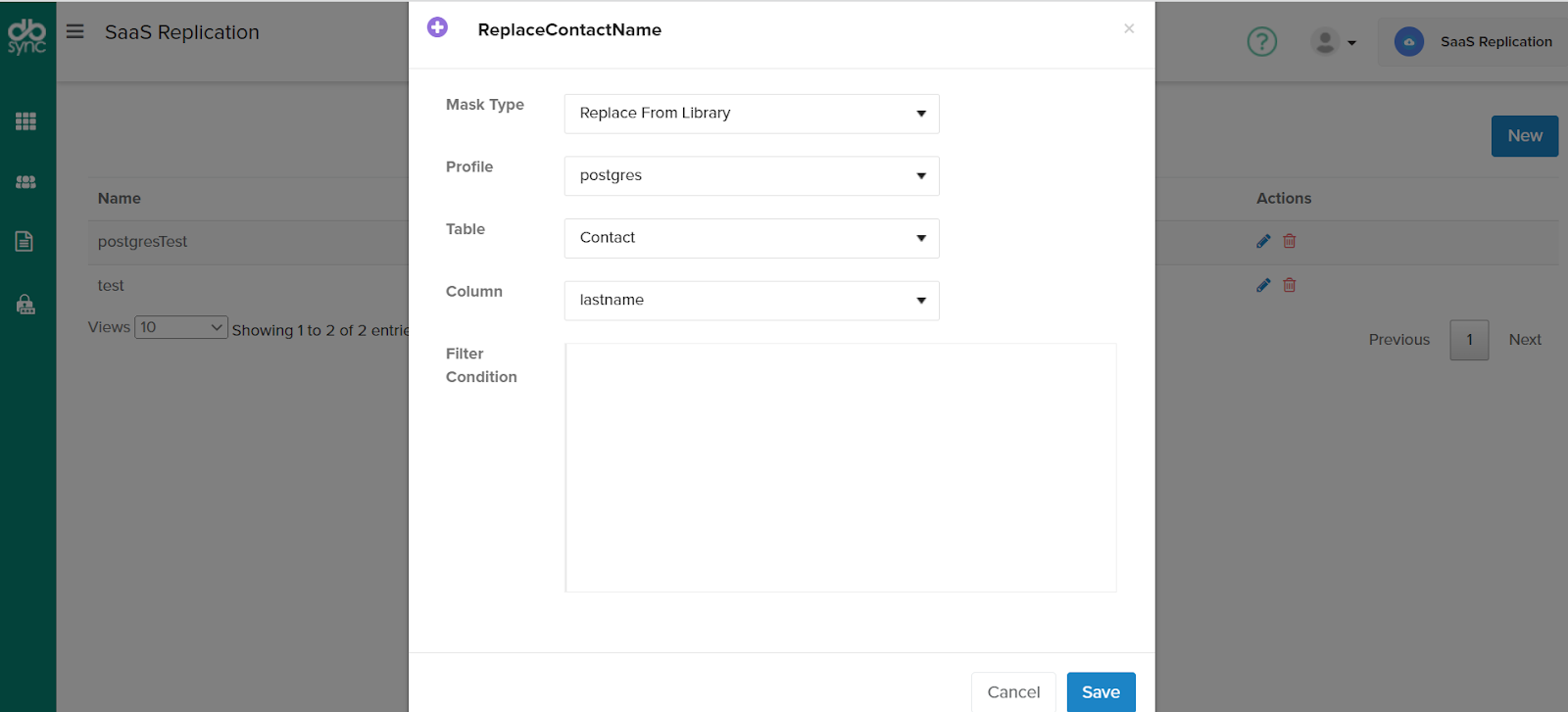
In order to help with defining custom mask patterns and types, you can use the already available data to substitute it or match a pattern or required characters to replace it with symbols or characters.
a. Substitution – Having a dictionary / dummy data to replace the actual data in the Warehouse
Example: Name can be replaced with certain predefined generic set of names already available within a table
b. Using Regular expressions – With regular expressions complex patterns within the data model can be identified and replaced with required characters ensuring data is not accessible or used by unauthorized users
Example: Instead of masking last 4 digits with predefined mask, the entire credit card numbers can be masked or you can also just mask first 12 digits with symbols and show the last four digits
c. Encryption – It is the advanced way to secure data, essentially data is masked using complex algorithms and is the most secure form of data masking. Secure and advanced methods are used to manage and share encryption keys for encrypting and decrypting data.
Interested in Salesforce Replication and Data Management solutions?
We offer a plug-and-play application that can help you get started in under 30 mins, with no cost for the trial. Check it out here:

Conclusion
In order to comply with privacy protection regulations, enterprises use data masking as one of the technologies, and with an ever-changing regulatory environment and requirements it is important to stay up to date with new and complex masking methods and techniques so it can be adapted and implemented within the existing architecture without much hassle.
With advanced and customizable masking patterns and techniques offered by DBSync, you can implement complex data masking patterns within your data silos and warehouses without needing to compromise on security or the performance.