Why your business needs a Cloud Data Lake

It feels like we’re all drowning in data these days, doesn’t it? Businesses are literally swimming in information from every direction imaginable: customer chats, buzzing IoT devices, internal systems, and so much more. Trying to make sense of this data deluge can feel like a Herculean task.
That’s where the cloud data lake swoops in, a centralized, super-flexible spot where you can stash all kinds of data, no matter the size. It’s truly empowering organizations to pull out incredible insights, spark innovation, and simply stay ahead of the game. What makes them such a game-changer? Think unbeatable flexibility, incredible cost savings, and lightning-fast agility. They’re truly becoming the backbone of how smart businesses handle their data.
This article dives deep into why cloud data lakes are so awesome, peeks into how they’re built, and shows how they play nicely with big platforms like Azure, Snowflake, and Salesforce Data Cloud.
Start Your 14-Day Free Trial
- Pre-built connectors and ready-made integration templates
- Real-time and bi-directional data sync
- Self-healing automation - zero babysitting
So, what’s a Cloud Data Lake, really?
Imagine trying to shove all your business’s incredibly diverse data into one perfectly organized, rigid box. That’s the old way. Now, we have cloud data lakes.
Now think of them as a meticulously sorted, vast, dynamic digital reservoir. This cloud-hosted expanse is engineered to swallow colossal amounts of raw, unadulterated data, preserving it in its pristine, original state. The magic happens because, unlike a traditional data warehouse that demands every piece of information be perfectly sculpted before it even enters (that’s “schema-on-write” thinking), a data lake takes a different, far more accommodating approach: “schema-on-read.”
This “schema-on-read” philosophy is a game-changer. It means you can simply ingest anything and everything, from the neatly structured rows of a database to the semi-structured jumble of JSON or CSV files, or even the sprawling complexity of untamed images and videos, without agonizing over pre-processing. There’s no upfront fuss, no rigid transformations forcing your data into a mold it wasn’t meant for.
Cloud data lakes leverage the bedrock of robust cloud object storage services like Amazon S3, Azure Data Lake Storage (ADLS), or Google Cloud Storage. A powerful foundation is about both: holding immense volumes and effortless processing of that raw information, for sophisticated analytics with BI tools like BigQuery, Snowflake, or Delta Lake.
What’s more, their inherent flexibility means they play beautifully across hybrid (mixing on-premise with cloud) and multi-cloud environments, offering businesses with unparalleled operational freedom and strategic agility. They truly empower you to ask any question of your data, whenever you’re ready.
Why Cloud Data Lakes can be a business’s smart glue
Ever feel like your data systems are constantly fighting you? If you’ve wrestled with clunky, “old-school” solutions, you know their limits. Good news: data lakes are a nimble, powerful ally for businesses navigating today’s complex data landscape. Here’s why:
- Scalability that just won’t quit: Imagine handling not just terabytes, but exabytes of data – effortlessly. Your data can simply grow, and the lake grows right with it, no frantic hardware calls needed.
- Flexibility that off-the-charts: Got spreadsheets, messy videos, or weird sensor data? Bring it on! Cloud data lakes gobble up all kinds of information, adapting smoothly as your analytical quests evolve, without forcing rigid structures.
- Surprisingly light on the wallet: With “pay-as-you-go” models and clever tiered storage, you only pay for what you actually use. This radically slashes those monstrous infrastructure costs and ongoing maintenance headaches.
- Agility you’ll love: This is huge. Cloud data lakes champion “self-service” access. Your teams can dive into the data, explore it, and find answers themselves, cutting out endless waits for IT reports. It’s about putting discovery power directly in their hands, enabling much faster decisions.
- True team player: Their superpower? Seamless integration. Whether it’s your existing ETL tools, cutting-edge machine learning platforms, or popular apps like Salesforce, cloud data lakes hook up beautifully. This just makes your entire data workflow smoother and far more productive.
Ultimately, by bringing all your diverse data into one smart, centralized hub, cloud data lakes effectively demolish those annoying data silos. This doesn’t just make life easier; it genuinely empowers organizations to unearth deeper, richer insights that truly drive better, smarter decisions, streamline operations, and ultimately deliver an even more fantastic customer experience.

 Sync data from Azure Data Lake Gen2 to SQL Server
Sync data from Azure Data Lake Gen2 to SQL Server

 Sync data from PostgreSQL to Snowflake
Sync data from PostgreSQL to Azure Data Lake Gen2
Sync data from PostgreSQL to Snowflake
Sync data from PostgreSQL to Azure Data Lake Gen2
Core capabilities: The synapses of a data lake
Cloud data lakes offer a genuinely transformative way to handle your data. Here are the top perks, along with some real-world scenarios:
1. Unmatched scalability and performance
Cloud data lakes plug directly into the nearly limitless power of giants like AWS, Azure, and Google Cloud. Whether you’re tucking away terabytes of IoT sensor data or petabytes of customer records, platforms like Azure Data Lake Gen2 or Amazon S3 simply scale on demand. You won’t see a performance hiccup. They auto-adjust their compute and storage resources to match your needs, keeping your real-time analytics running smoothly. Think of a major retailer: they can ingest millions of daily transactions, process them with Snowflake, and generate live inventory forecasts without a single worry about server capacity. That’s the true power of cloud scale.
2. Seriously cost-effective storage
Cloud data lakes are budgeting wizards, masters of optimizing expenses. This comes from smart tiered storage and pay-as-you-go models. Services like Azure Blob Storage offer “hot,” “cool,” and “archive” tiers, while S3 Intelligent-Tiering automatically moves less-accessed data to cheaper storage classes. This means you can finally ditch that expensive on-premise hardware and its never-ending maintenance bills. For instance, a financial institution can store years of transactional data in S3 Glacier for compliance at a fraction of the traditional cost, all while keeping frequently accessed data in S3 Standard for quick analytics.
| Storage Tier | Use Case | Cost Efficiency |
| Hot (S3 Standard, Azure Hot) | Frequent access for real-time analytics | Higher cost, optimized for performance |
| Cool (S3 Infrequent Access, Azure Cool) | Less frequent access, e.g., historical reports | Lower cost, slight latency |
| Archive (S3 Glacier, Azure Archive) | Long-term retention for compliance | Lowest cost, higher retrieval time |
3. Incredible flexibility for diverse data
Unlike data warehouses, which really prefer their data neatly lined up, cloud data lakes embrace everything. We’re talking structured numbers, semi-structured files, and even raw, messy unstructured data – all with total ease. This flexibility opens up a vast world of possibilities: think digging into customer sentiment from social media or processing that endless stream of data pouring in from IoT sensors. Picture a manufacturing firm, for instance, storing machine logs (raw!), ERP data (organized!), and XML configurations (somewhere in between!) all in one Delta Lake. They can then instantly use tools like Databricks to analyze equipment performance and even predict future maintenance needs.
4. Powering advanced analytics and machine learning
This is where the magic truly unfolds. Cloud data lakes hook up effortlessly with industry powerhouses like Snowflake, BigQuery, and Azure Synapse. This connection lets you build seriously sophisticated analytics workflows. Machine learning algorithms can then churn through all that raw data, swiftly uncovering hidden patterns, predicting future trends, or even spotting anomalies before they become problems. Imagine a healthcare provider, for example, using Snowflake Data Cloud to analyze patient records and anticipate potential disease outbreaks. That’s data becoming truly predictive.
5. Robust security and governance
When we talk about something as crucial as your data, security and governance aren’t just technical terms; they’re the absolute bedrock. Cloud providers grasp this entirely, which is precisely why they pour immense resources into fortifying your data lake. We’re discussing top-tier encryption, safeguarding your data whether it’s simply sitting still (at rest) or zipping through networks (in transit).
But it’s far more than just strong locks. It’s about genuine control. Platforms like Azure Data Lake Gen2 and AWS S3 offer incredible granularity, you literally decide who sees what, down to specific files or even portions of data. This isn’t just a best practice; it’s non-negotiable for adhering to regulations like GDPR, HIPAA, and SOX. Plus, tools like AWS Glue Data Catalog act like your personal data librarians, making information easy to find, understand, and track. It’s about ensuring your valuable insights never come at the expense of absolute security or compliance.
6. Seamless integration with other systems
Here’s another big win: cloud data lakes are designed to be the ultimate team players. They play nicely with virtually everything you already use, from your essential ETL tools to popular SaaS applications, and even newer setups like data lakehouses. Think about it: platforms like Salesforce Data Cloud and QuickBooks link up effortlessly, enabling real-time data flows without a hiccup. And for those legacy systems still on-premise? No worries at all! Hybrid architectures allow you to seamlessly blend your existing infrastructure with cloud lakes, ensuring a smooth, disruption-free transition. Your entire data ecosystem just works better, together.
7. Awesome agility for business users
One of the coolest, most empowering aspects of cloud data lakes is the freedom they grant to business users. Forget those old-school systems demanding you perfectly pre-define data structures before storage (that “schema-on-write” headache!). Data lakes flip the script with a “schema-on-read” approach.
What does this truly mean for, say, a marketing or sales manager? It means you’re no longer stuck waiting for IT to pre-process everything or craft a rigid report. You can literally dive straight into the raw data and start exploring. Imagine combining social media comments, website click data, and sales figures to see what campaigns are really resonating. With intuitive tools like BigQuery or Snowflake’s user interfaces, you ask questions of this diverse data on the fly, without needing a developer’s help. This “try-it-and-see” freedom dramatically accelerates discovery, letting business teams uncover insights and adapt far more rapidly than ever. It’s about putting the power of data exploration directly into the hands of those who need it most, cutting out traditional bottlenecks.
Comparing Cloud Data Lake vs. Data Warehouse vs. Data Lakehouse
To truly grasp the value of cloud data lakes, it helps to see how they stack up against their cousins: data warehouses and data lakehouses.

It’s worth noting that data lakehouses, like those powered by Databricks, are kind of the best of both worlds. They combine the flexibility of data lakes with the structured goodness of data warehouses, offering a unified powerhouse for all your analytics and machine learning needs.
A peek into the architecture of cloud data lakes
Primarily, data lakes have massive cloud object storage like Amazon S3 or Azure Data Lake Storage (ADLS). But there’s several more layers than just storage.
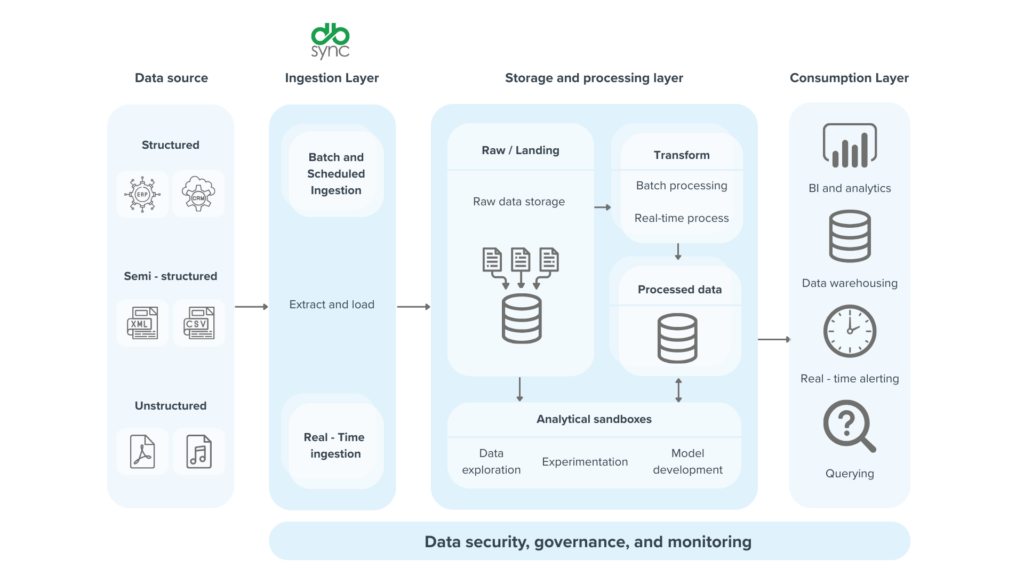
- Ingestion layer: where data streams in from different sources: customer interactions, IoT devices, business apps. Tools like Azure Data Factory or AWS Kinesis are like the highways bringing all that diverse information into the lake.
- Processing engines: where the raw material starts to become valuable. It consists of an engine like Apache Spark (used through services like Databricks) or Snowflake, which can crunch through vast amounts of data to transform, clean, and prepare for analysis.
- BI or Analytics layer: where tools like Snowflake Data Cloud, BigQuery, or Azure Synapse connect directly to your data lake. So you can run complex queries and build dashboards to pull out critical insights. This layer is all about making the data accessible and actionable for decision-making teams.
It’s like a factory for your data, where each layer plays a crucial role in turning raw data into meaningful intelligence.
Navigating the data lake paralysis
Cloud data lakes aren’t magic wands. Like most potent tools, they have pitfalls. And knowing them, is the first step to mastering them.
Here are a few key obstacles and some ways to overcome them:
- The data swamp: Without proper management, your data lake can become a chaotic mess, burying any useful insights. Staying organized is absolutely essential.
- Migration Headaches: Moving huge amounts of old data to the cloud can be an expensive and long project. It really needs to be precisely planned.
- The Stealth of Cost Creep: Cloud solutions save money, but if you’re not careful, those “pay-as-you-go” bills can quickly add up. You really need to watch your usage closely.
- Continuous Governance: To ensure data in the lake is always accurate and compliant, requires solid frameworks and guidelines. It’s a continuous and demanding effort.
But here’s the encouraging news: these aren’t dead ends. Modern platforms like Azure Synapse and Snowflake have built-in governance and smart cost-optimization tools.
Cloud vs. on-premise data lates: Picking the core of your business’s intelligence
Running data lakes on on-prem servers demands heavy capital, continuous upkeep, and niche talent. Cloud data lakes, however, present a simpler proposition:
- Zero upfront capital: Forget huge initial investments; physical infrastructure simply vanishes.
- True global reach: Your data becomes instantly accessible to teams anywhere, anytime.
- Blazing deployment speed: Spin up powerful lakes in hours instead of months. Time-to-insight is significantly shorter.
- Naturally integrated: They effortlessly fit into your ecosystem, connecting with BigQuery, Snowflake, or Salesforce Data Cloud.
For small or growing businesses, this is a game-changer, leveling the playing field against larger rivals.
The evolving mind: Future of data lake
Cloud data lakes are becoming the main foundation for businesses exploring big data, IoT, and machine learning. New developments, like Delta Lake and Snowflake Data Cloud, keep making them more powerful. Plus, using smart multi-cloud plans makes them even stronger and more flexible.
If you invest in a cloud data lake now, you’re essentially preparing your data systems for the future. Data lakes will power innovations and give your business the edge over competitors.
What is a cloud data lake?
A cloud data lake is a centralized repository that stores structured and unstructured data at scale, hosted on cloud infrastructure, enabling flexible data management and analytics.
How does a cloud data lake improve data accessibility?
It allows data from multiple sources to be stored in a single location, making it easily accessible for analysis, reporting, and integration with applications like Salesforce or QuickBooks.
What are the cost benefits of using a cloud data lake?
Cloud data lakes reduce infrastructure costs by leveraging scalable cloud storage, eliminating the need for on-premise hardware and maintenance.
How does DBSync utilize cloud data lakes for integration?
DBSync’s platform integrates cloud data lakes with SaaS applications, enabling seamless data replication and synchronization for enhanced business intelligence and analytics.
What security features do cloud data lakes offer?
They provide robust security through encryption, access controls, and compliance with standards like SOC 2, ensuring data protection and regulatory adherence.